Getting Started with the Draft API
This document guides you on how to use Draft API to perform the following actions with documents through your command line interface (CLI):
- Create
- Edit
- Publish
- Circulate
Requirements
Ensure you understand what HTTP and API are before you start reading this document.
This guide explains the rest of the concepts you might need.
Authentication
To access the API, you need an access token. Follow Using Developer Access Tokens to Access the Arc XP APIs guide to obtain one.
In the rest of this document a <TOKEN> refers to your access token. In such cases, replace the <TOKEN> value with the value of your token.
General Concepts
In this section, we introduce some important concepts of the Draft API.
Document
At Arx XP, a document is any piece of content. A document can be of any type: A story, an image, or a video.
All documents share the following common attributes:
- A unique identifier (ID): A string of characters and numbers, like
OXSDHY3JOFFCFKJUVGEPUB77YQ, that lets you uniquely identify and find the content within your organization. - A type: States whether a document is a story, an image, or a video.
- A couple dates: A typical creation date and the date the document was last updated.
- Revisions: One or more versions of your document, in chronological order.
Draft API is for story documents only.
- To work with image and gallery documents: See Photo Center API.
- To work with video documents: See Video Center API.
Revisions
Every time you save a document, you create a new revision or version. In the rest of this document, we use the term revision.
Like documents, revisions have a number of common attributes:
- They belong to a document. Each revision is associated with a single document, and each document can have one or multiple revisions.
- They are immutable. After a revision is created, it can never be changed. This is important for history and caching. If for any reason you want to change a revision (say you found a typo), then you must create a new revision.
- They have a unique identifier. Because revisions are immutable, they receive their own identifier. The identifier format is the same as the identifier that documents use. It is unique across the organization.
- They have a type. The type should be the same as the document’s type: story, image, video, etc.
- They hold content, in the form of an ANS Document.
Publication model
Documents are made of two mutually exclusive sets of a draft revision and published revision.
When creating a document, you must supply a draft revision. As you work with your document, it reaches a ready state, and you want to publish it. When you do, a copy of the current draft is created, and it becomes a new published revision. That new published revision is then cloned, and it becomes the current draft (more on that later in the guide).
The following illustration shows this process:
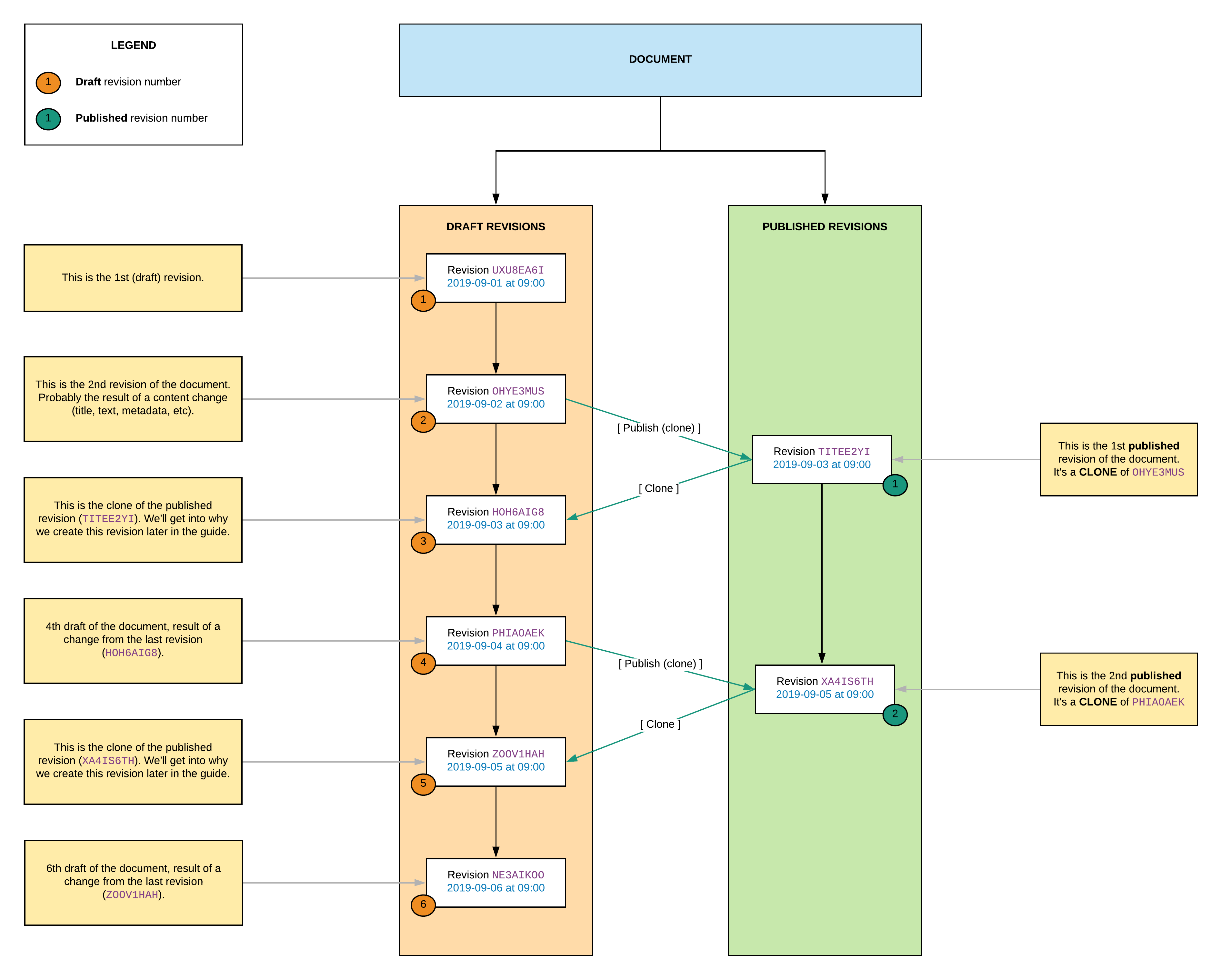
Let’s describe what happens:
- The document is created on
2019-09-01. At this time, the document contains one draft revision and no published revision. - On
2019-09-02, a second draft is created. The user updated the document with content, maybe a title, text, and metadata. - The next day, on
2019-09-03, the user decides that their work is ready for publishing. They publish the current draft (OHYE3MUS). Publishing the current draft creates a copy of the revision (TITEE2YI). This new revision becomes the first published revision. The published revision is then copied and becomes the new draft (HOH6AIG8). - The user makes some additional changes, and creates a new draft revision on
2019-09-04(PHIA0AEK). - The previous changes to the document are important, and the user decides to publish them. To do so, they call the publish endpoints, which again copies the current draft to create a new published revision (
XA4IS6TH). A new draft is created as well (ZOOV1HAH). - A final modification is made to the document, which creates a new draft revision (
NE3AIKOO). This draft revision is not published.
A few comments:
- When you publish a document, a copy of the current draft revision is created and saved as the current published revision.
- As a result, a published revision always has a counterpart (as in, a clone) in the draft revision set. It is not possible to publish a revision that has not first been a draft.1
- After a new published revision has been created, it is copied back as the new current draft. This is to ensure that the “last update” date of the “draft” branch is always after the “last update” date of the “published” branch. This way, there is never any confusion as to which version of the content is “latest”. The current draft is always the “latest” version of the document (though, of course, it may not reflect what is currently published on the web).
In the rest of this document, this schema will be reused to illustrate what happens as API calls are made.
Circulations
Working with a document is great, but ultimately you want to publish it on the web. In Arc XP, an organization is comprised of several websites. And each website can have multiple sections:
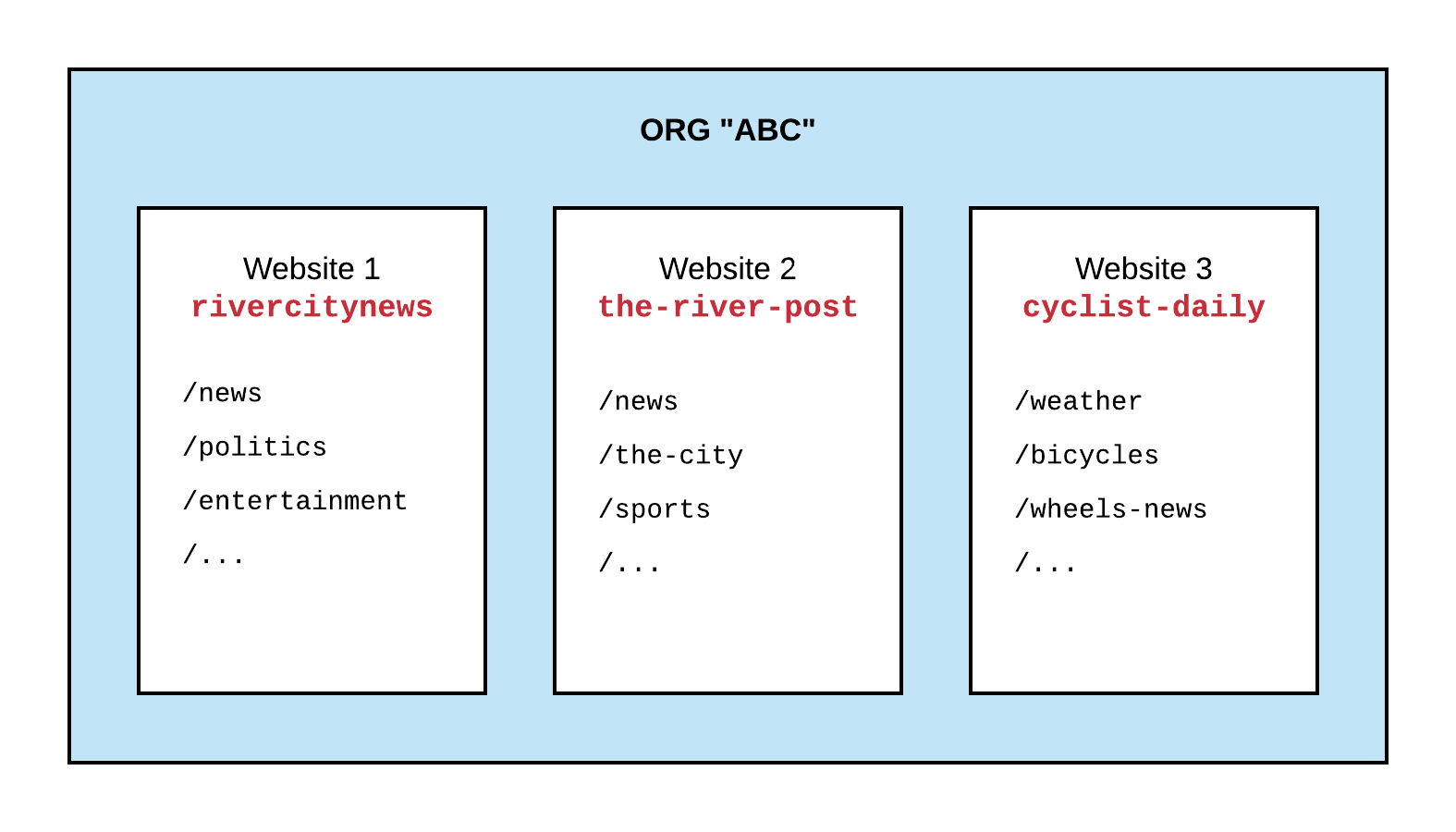
Circulations, together, define:
- Which websites a document can appear on
- Which website is the primary website (aka canonical)
- The URL of the document on each website
- For each website, which sections the document can appear in
- For the primary website, which section is primary
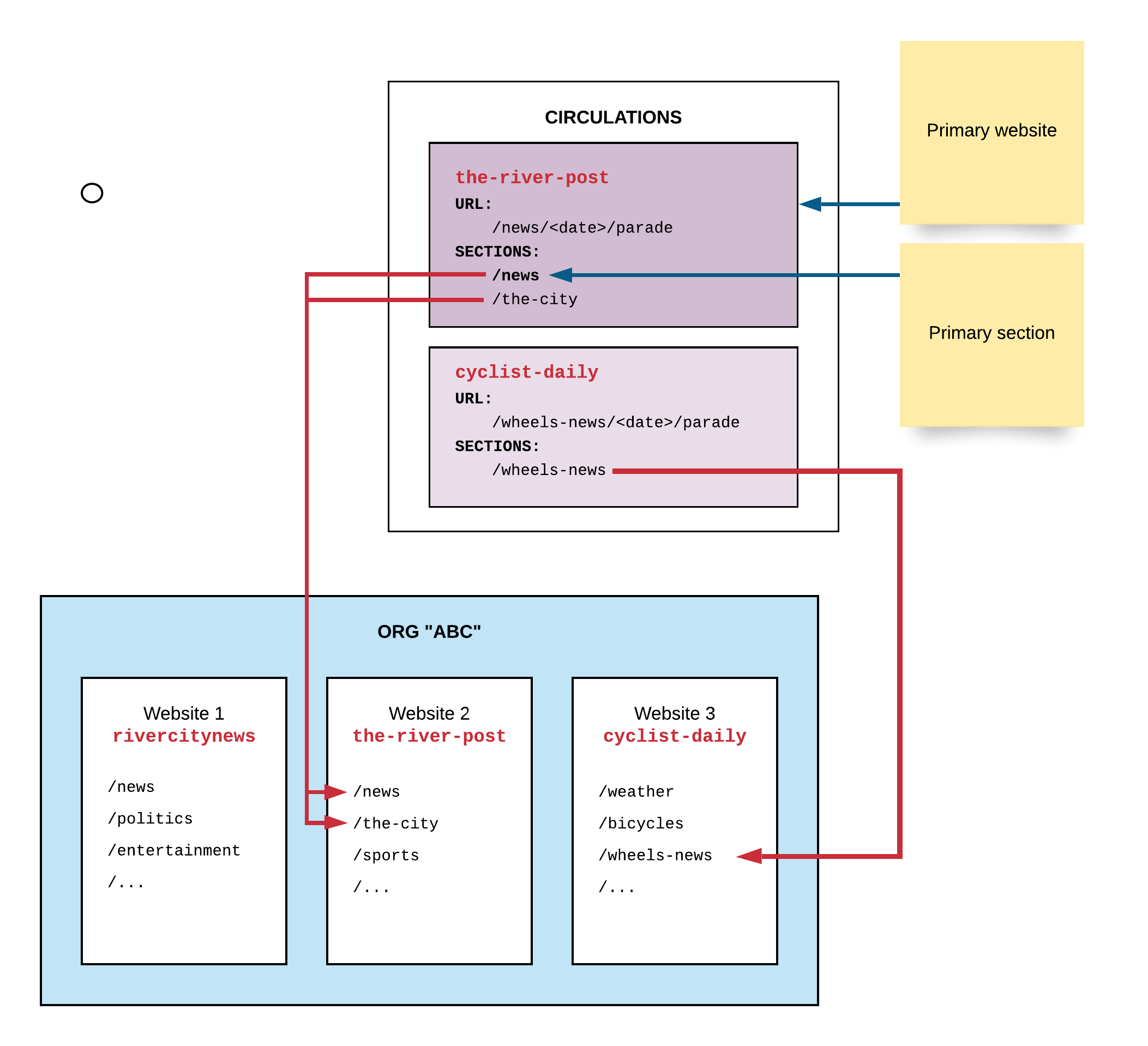
In the schema above, the document:
- Appears on 2 websites,
the-river-postandcyclist-daily the-river-postis the primary website- Is not present/circulated on the website
rivercitynews
On the-river-post:
- It has the URL
/news/<date>/parade - It belongs to the section
/news, which is the primary section - It also belongs to the section
/the-city
On cyclist-daily:
- It has the URL
/wheels-news/<date>/parade - It belongs to the section
/wheels-news - It does not belong to any other section
Circulations and Revisions
It is important to note that creating/updating/deleting the circulation of a document does not change or affect its revision:
- Revisions are about content
- Circulations are about distribution
In particular, you can create a circulation for a document before it is published. This, in itself, will not publish the document. Once the document is published, however, it will show on the websites & sections defined by the circulations.
Creating a new document
Creating a new document requires you to provide initial valid ANS:
curl --request POST \ --header 'Authorization: Bearer <TOKEN>' \ --header 'Content-Type: application/json' \ --url https://api.{{org}}.arcpublishing.com/draft/v1/story \ --data '{ "type": "story", "version": "0.10.10", "canonical_website": "cyclist-daily", "headlines": { "basic": "My new story" } }'You will get the same response back (for example, the document):
{ "id": "ZHXE3Y6OJVAUFDJIM3M43AV5KM", "draft_revision_id": "EQFXJDR4CJDGPKCN7PA4G3UMAQ", "created_at": "2019-09-01T09:00:00Z", "type": "STORY"}You can view the revision by making the following request:
curl --request GET \ --header 'Authorization: Bearer <TOKEN>' \ --url https://api.{{org}}.arcpublishing.com/draft/v1/story/ZHXE3Y6OJVAUFDJIM3M43AV5KM/revisionResponse:
{ "revisions": [ { "type": "DRAFT", // Draft or published "id": "EQFXJDR4CJDGPKCN7PA4G3UMAQ", // Revision ID "document_id": "ZHXE3Y6OJVAUFDJIM3M43AV5KM", // Document ID "created_at": "2019-09-01T09:00:00Z", // Creation date "ans": { // Content of the revision "version": "0.10.10", // ANS - Version "type": "story", // ANS - Document type "created_date": "2019-09-01T09:00:00Z", // ANS - Creation date "last_updated_date": "2019-09-01T09:00:00Z", // ANS - Updated at date (= creation) "headlines": { // ++ Added "basic": "My new story" // ++ Added } // ++ Added } } ]}Validating the document
You can validate a document’s ANS using this POST endpoint in the ANS service:
curl --request POST \ --url https://api.{{org}}.arcpublishing.com/ans/validate/{{ans version}} \ --header 'Authorization: Bearer <TOKEN>' \ --header 'Content-Type: application/json' \ --data '{ "canonical_website": "test-website", "headlines": { "basic": "Test Document", "meta_title": "Adding meta title" }, "owner": { "id": {{org}} }, "type": "story", "version": "{{ans version}}", "slug": "testDocument", "revision": { "user_id": "test_user" }}'Use the same {{ans version}} as the document’s ans.version key in the URL path of the endpoint. For example, if your document is "version": "0.10.10", then the endpoint is https://api.{{org}}.arcpublishing.com/ans/validate/0.10.10.
If the document ANS is valid, the endpoint returns true.
Looking at the document
You can get the document back using the GET endpoint:
curl --request GET \ --header 'Authorization: Bearer <TOKEN>' \ --url https://api.{{org}}.arcpublishing.com/draft/v1/story/ZHXE3Y6OJVAUFDJIM3M43AV5KM# This returns a `Document` objectYou can also get the list of revisions (added /revision):
curl --request GET \ --header 'Authorization: Bearer <TOKEN>' \ --url https://api.{{org}}.arcpublishing.com/draft/v1/story/ZHXE3Y6OJVAUFDJIM3M43AV5KM/revision# This returns a list of revision summaries:# [# revision summary,# revision summary,# revision summary,# ...# ]Response:
{ "revisions": [ { "type": "DRAFT", // Draft or published "id": "EQFXJDR4CJDGPKCN7PA4G3UMAQ", // Revision ID "document_id": "ZHXE3Y6OJVAUFDJIM3M43AV5KM", // Document ID "created_at": "2019-09-01T09:00:00Z", // Creation date "ans": { // Content of the revision "version": "0.10.10", // ANS - Version "type": "story", // ANS - Document type "created_date": "2019-09-01T09:00:00Z", // ANS - Creation date "last_updated_date": "2019-09-01T09:00:00Z" // ANS - Updated at date (= creation) } } ]}So at this point, the document looks like this:
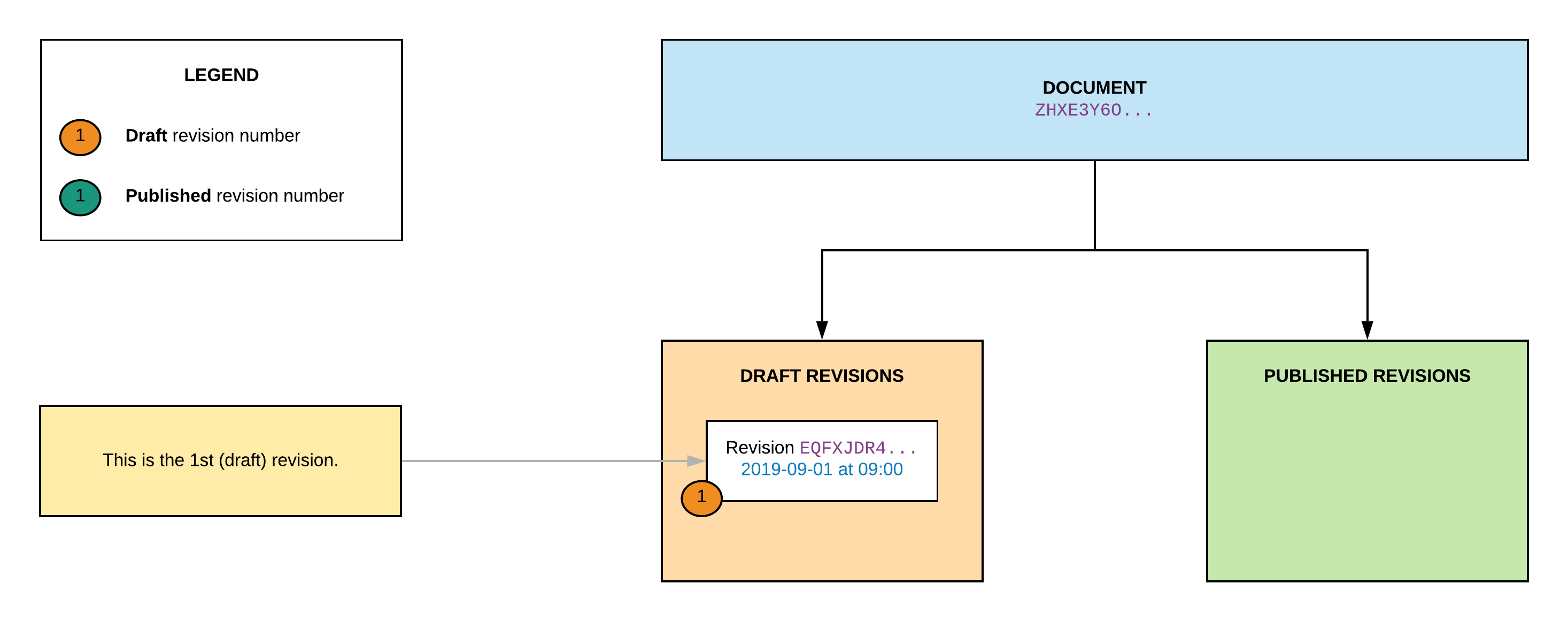
Updating the document
Updating the document is just as easy: simply provide the ANS.
curl --request PUT \ --header 'Authorization: Bearer <TOKEN>' \ --header 'Content-Type: application/json' \ --url https://api.{{org}}.arcpublishing.com/draft/v1/story/ZHXE3Y6OJVAUFDJIM3M43AV5KM/revision/draft \ --data '{ "ans": { "_id": "ZHXE3Y6OJVAUFDJIM3M43AV5KM", "type": "story", "version": "0.10.10", "canonical_website": "cyclist-daily", "headlines": { "basic": "My updated story (v2)" } } }'For creating a document, POST /draft/v1/story was called. To update the document, you will create a new draft revision. The call now looks like this: PUT /draft/v1/story/ID/revision/draft. This can be decomposed like so:
/draft # root (or base path) /v1 # current version of the API /story # the content type (story, video, image, ...) /ID # the document ID /revision # the document sub-resource /draft # type of revisionYou can do a 3rd update, just the same way (updated headline):
curl --request PUT \ --header 'Authorization: Bearer <TOKEN>' \ --header 'Content-Type: application/json' \ --url https://api.{{org}}.arcpublishing.com/draft/v1/story/ZHXE3Y6OJVAUFDJIM3M43AV5KM/revision/draft \ --data '{ "ans": { "_id": "ZHXE3Y6OJVAUFDJIM3M43AV5KM", "type": "story", "version": "0.10.10", "canonical_website": "cyclist-daily", "headlines": { "basic": "My updated story (v3)" } } }'The document now looks like this:

The document is ready to be published. There are 2 things left to do:
- Define its circulation
- Publish it
Circulating the document
The story is important, so it’s going to be circulated on more than 1 section/website. Just like the examples before, the document will be circulated to 2 websites and 3 sections. We’ll pick /news on river-city-post to be the primary section:
# First websitecurl --request PUT \ --header 'Authorization: Bearer <TOKEN>' \ --header 'Content-Type: application/json' \ --url https://api.{{org}}.arcpublishing.com/draft/v1/story/ZHXE3Y6OJVAUFDJIM3M43AV5KM/circulation/river-city-post \ --data '{ "document_id": "ZHXE3Y6OJVAUFDJIM3M43AV5KM", "website_id": "river-city-post", "website_url": "/news/2019/09/04/parade", "website_primary_section": { "type": "reference", "referent": { "id": "/news", "type": "section", "website": "river-city-post" } }, "website_sections": [ { "type": "reference", "referent": { "id": "/news", "type": "section", "website": "river-city-post" } }, { "type": "reference", "referent": { "id": "/the-city", "type": "section", "website": "river-city-post" } } ] }'# Second websitecurl --request PUT \ --header 'Authorization: Bearer <TOKEN>' \ --header 'Content-Type: application/json' \ --url https://api.{{org}}.arcpublishing.com/draft/v1/story/ZHXE3Y6OJVAUFDJIM3M43AV5KM/circulation/cyclist-daily \ --data '{ "document_id": "ZHXE3Y6OJVAUFDJIM3M43AV5KM", "website_id": "cyclist-daily", "website_url": "/wheels-news/2019/09/04/parade", "website_primary_section": { "type": "reference", "referent": { "id": "/wheels-news", "type": "section", "website": "cyclist-daily" } }, "website_sections": [ { "type": "reference", "referent": { "id": "/wheels-news", "type": "section", "website": "cyclist-daily" } } ] }'The document now looks like this:
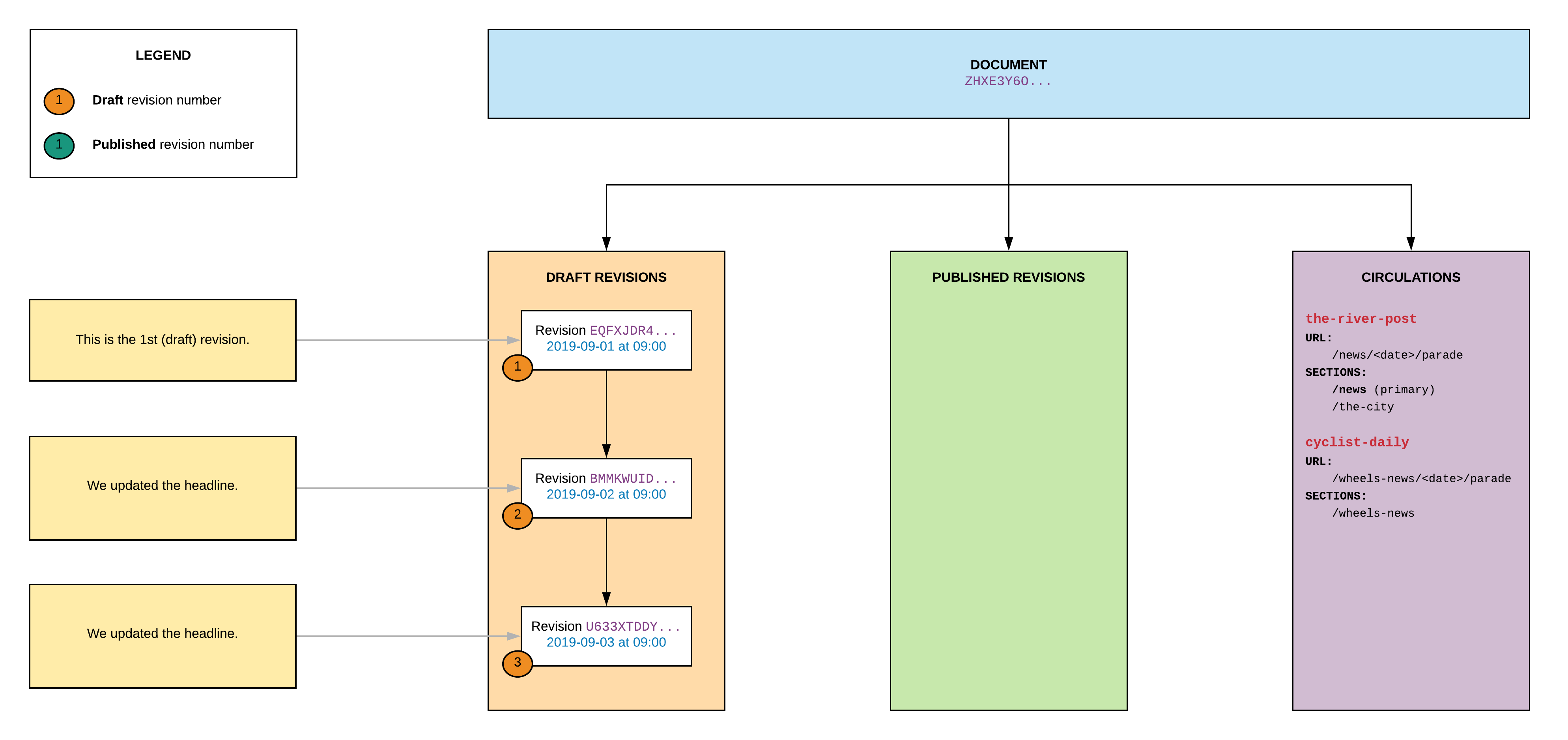
Looking up circulations
You can easily check the current circulations (with a ‘s’, since circulations are per website):
# 1st websitecurl --request GET \ --header 'Authorization: Bearer <TOKEN>' \ --url https://api.{{org}}.arcpublishing.com/draft/v1/story/ZHXE3Y6OJVAUFDJIM3M43AV5KM/circulation/river-city-post
# 2nd websitecurl --request GET \ --header 'Authorization: Bearer <TOKEN>' \ --url https://api.{{org}}.arcpublishing.com/draft/v1/story/ZHXE3Y6OJVAUFDJIM3M43AV5KM/circulation/cyclist-dailyPublishing the document
The document is ready to be published. Let’s go ahead:
curl --request POST \ --header 'Authorization: Bearer <TOKEN>' \ --header 'Content-Type: application/json' \ --url https://api.{{org}}.arcpublishing.com/draft/v1/story/ZHXE3Y6OJVAUFDJIM3M43AV5KM/revision/published \Let’s look at the document now:
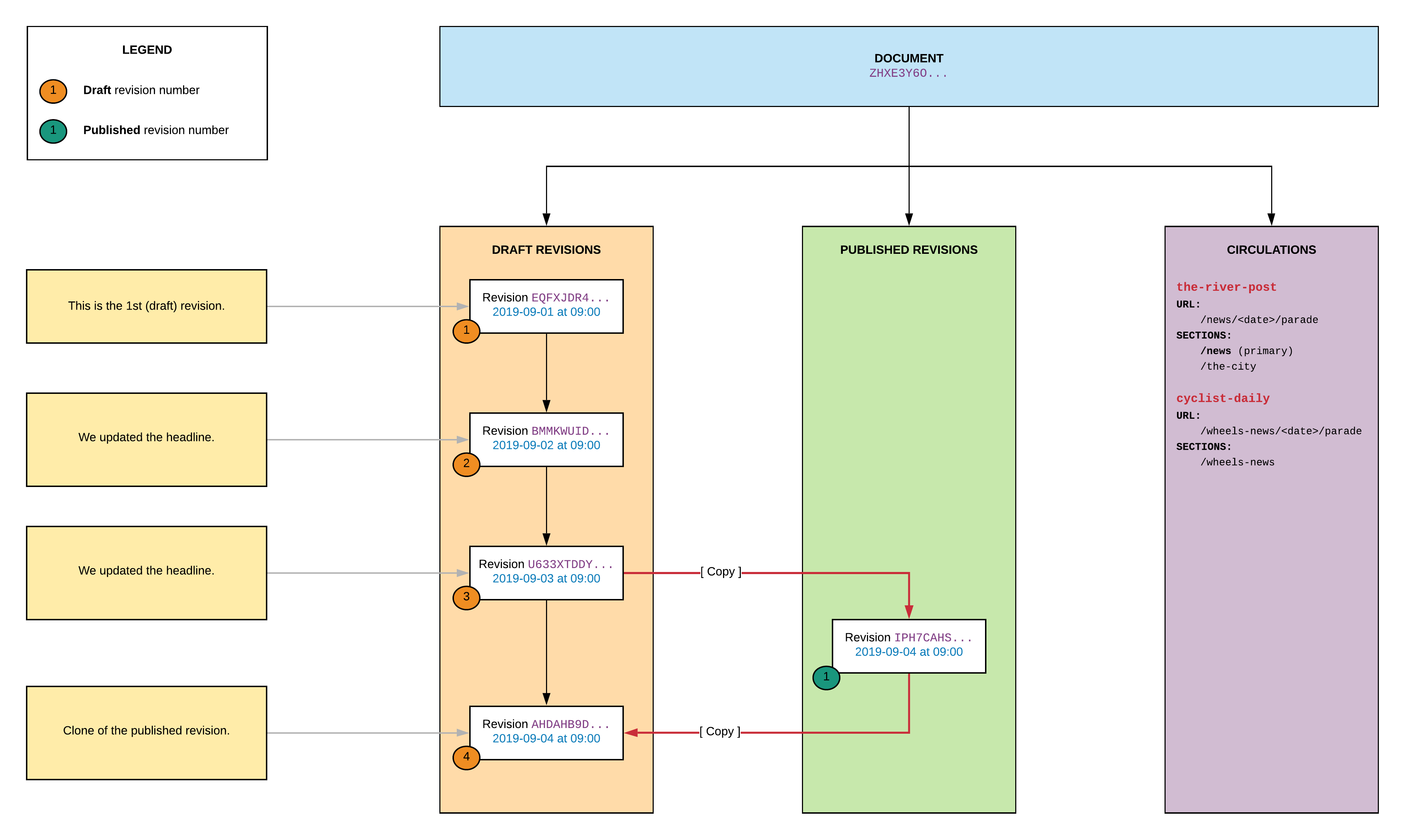
Publishing the document did the following:
- It created a copy of the current draft revision (
U633XTDDY...→IPH7CAHS...) - It published the newly created revision (
IPH7CAHS...) - It made a copy of the published revision and set it as the new draft revision (
AHDAHB9D...)
The document is now both published and circulated. Let the readers come!
Leveraging the Arc-Priority HTTP header
The Draft API leverages an HTTP header, Arc-Priority, to segment content that authors are actively working on from historical content. The Arc-Priority header allows for two values: standard and ingestion.
Always use the ingestion header when ingesting historical content, like when you’re moving from an old CMS to Arc XP. Don’t use the standard header when migrating. Use the standard header only if you’re ingesting current content into Arc XP that was authored in an external CMS that day. This is not a common use of the Arc XP APIs.
Setting the priority for migrated and legacy content to ingestion ensures that legacy content does not crowd out content your organization produces within Composer. Failure to use this header could lead to stale content on your site.
Note that content in the ingestion lane is not sent to WebSked and is therefore not available to be added to Collections.
When interacting with the Draft API to manage ingested content (legacy or automated), you must add the following header: Arc-Priority: ingestion.
If you have an IFX integration listening for story:update and are performing programmatic updates, include header Arc-Priority: ingestion; IFX will ignore this message and it prevents an infinite loop.
Footnotes
-
This is not always true for content created outside of Draft API, as other systems may not enforce this workflow. ↩