Live Blogging - IFX integration (headless clients)
Third-party integration
For this solution, live blog content is created in a third-party external system (such as Scribble) and imported into Arc XP either through a Power Up or as raw HTML.
Scribble which was acquired by Rock Content: https://rockcontent.com/
| PROS | CONS |
|---|---|
| Easy integration - APIs likely already exist or can be easily adapted | Adding another tool to the editorial workflow, maintaining content outside of Arc XP |
| Choice of system - maintain legacy system or choosing new third-party provider | Creating and maintaining a relationship with third-party provider or legacy system |
| Content hidden from crawlers | |
| Impact on performance due to client-side fetching of third-party data | |
| No-to-little influence on visuals and display |
Custom Power Ups in Composer
This solution allows for the content to be created completely in Arc XP and not in a third-party tool. By having all content come through Arc XP’s regular process, the content is available for crawlers and other search engines, such as Queryly.
We recommend using a subtype for a live blog, so you can:
- resolve live blogs to an alternative template
- remove the live blog content from section fronts and feeds like RSS, FBIA, etc.
- create a targeted query
There are two levels of complexity for this solution, based on your requirements.
Single author
When you need to live blog, but always only with one author at a time, then the solution is simple and does not require an IFX Integration or any other back-end work.
Requirements
- Timestamp Power Up
| PROS | CONS |
|---|---|
| No third-party service required | Custom Power Up build |
| Content available to crawlers | |
| In charge of visuals and display | |
| All Composer content available |
Multiple authors
When you require multiple authors contribute to one live blog, the architecture becomes a bit more complicated. The main reason for that is the limitation of Composer to allow only one contributor at a time and locking the story.
To allow for multiple authors, the system splits the live blog into multiple stories in Composer. There’s a parent article and multiple child articles, where the system then copies all content from the child stories to the parent story. The parent article is the resulting live blog that is published.
An IFX integration performs the copying process on a child story publish. Both parent and child need to be set up to trigger IFX events (subtype, label).
Requirements
- Timestamp Power Up
- Customizing article body chain (Themes only)
- IFX
| PROS | CONS |
|---|---|
| No third-party service required | Content is spread in multiple stories so edits and corrections are more complex |
| Content available to crawlers | Custom Power Up |
| In charge of visuals and display | |
| All Composer content available |
Editorial workflow
- An author creates the parent story from a template and shares the Arc ID with the contributors
- The contributors create child stories from a template and add the Arc ID in the live parent id label
- You can add child stories at any time.
- To remove child story content, you must republish the child story with no content. Deleting the child story does not remove the content from the parent.
- On publish of a child story:
- The system immediately unpublishes the story.
- The system copies the content of the child story into the parent story.
- The system copies the child story Arc ID and the child story author(s) into the Power Up data when copying the content to the parent to identify where each entry comes from.
Architecture
Most of this solution is based on regular Arc XP content and processes that are already in place. In the following diagram, you can see that only the blue entities require a custom buildout, not provided by Arc XP.
The key entries of this solution are:
- child stories should never be published and made publicly accessible
- the parent story should not be edited while contributors are active
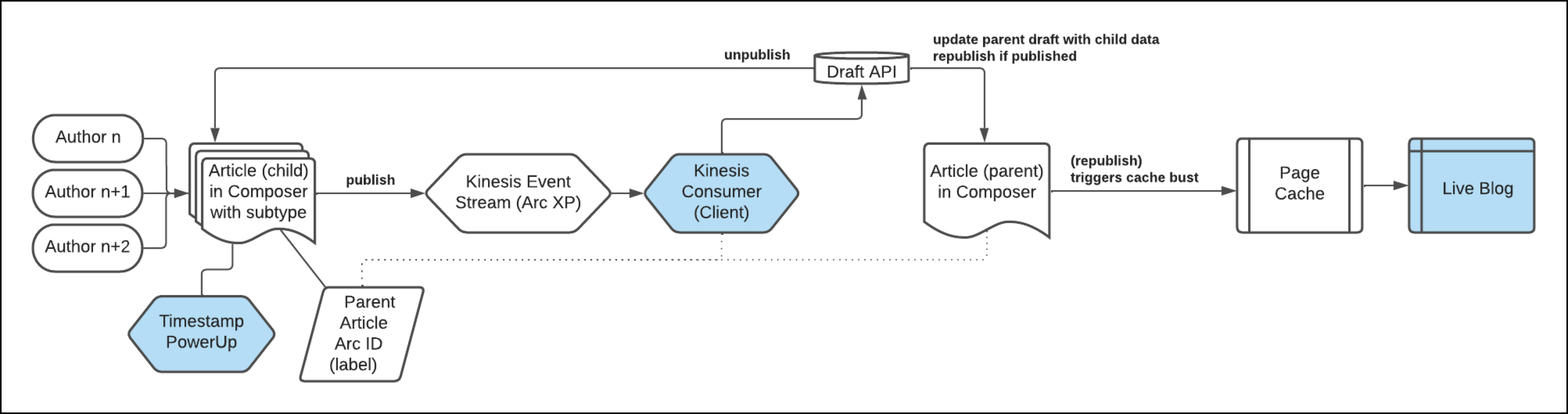
IFX event listener
IFX provides updates on operations performed on stories (full list here), where the IFX integration must filter through and forward the event only when certain criteria are met. See IFX endpoints.
For the live blogging solution, the criteria is:
- subtype is live blog child story [live-story-writer]
- Arc ID of the parent is provided [labels.parent_live_id.text]
The steps inside the IFX integration are:
- fetch the parent story draft
- remove all entries from the child story in the parent story
- inject child story ID and authors into the Timestamp Power Up
- merge all child story content_elements and parent story content_elements
- update display_date on the parent story
- put modified parent story draft back into Draft API
- unpublish the child story
- re-publish (if already published) the parent story
Common Assets
Timestamp Power Up
The Timestamp Power Up is the tool providing the timestamp to the blog entries, dating them inside your live blog. The timestamp also defines when a new entry starts, allowing you to sort the entries in descending order in the front end, with each content entry attached to the timestamp.
UI
The Timestamp Power Up is a custom embed that contains all information you want to attach to each individual live entry. The crucial part is that a timestamp is created when you add it and that you can edit it afterwards. The timestamp should be displayed when outside of adding and editing.
Unique to the multiple-author solution is the availability of the child story Arc ID and author(s) in the ANS (see in the Data Format). Providing these items as read-only on the Power Up helps authors to communicate necessary changes, or to perform changes themselves.
Front end
Custom embeds have a specific custom_embed subtype as a content_element and need to be treated individually in the front-end code. You can decide how this looks and what to include.
Data format
The format for a custom embed is already provided in the ANS Schema for custom_embed. This schema outlines the necessary fields for Arc XP. Custom embeds contain a field, embed.config, where all custom data must be stored. The format of the data inside of embed.onfig is up to you.
If your’e using the multiple-author solution, the Lambda is manipulating the Timestamp Power Up data in this step, and you must consider that those fields are available for the Lambda and are not already in use. Our recommendation is that the Lambda data be located in the content_element’s additional_properties field. Here’s an example of a potential content_element output:
{ "_id": "B25FR7E5HJGDHOYCZVVZMHOO4A", // autogenerated, unique inside of Story "type": "custom_embed", "subtype": "timestamp_Power Up", // customizable in Composer settings, needs to match Lambda "additional_properties": { "livestory_child_story": "SVFJ6BKYV5FBFNEGXUOGBLYTFI" // written & used in Lambda to target copied data }, "embed": { "config": { "additional_properties": { "livestory_author": "credits.by[x].byline", // written by Lambda used in Composer/Display "livestory_child_story": "childStory._id" // written by Lambda used in Composer }, "dateTimeField": 1660041686320 // timestamp }, "id": "timestamp-6915", // required, customizable, unique inside of Story (randomized number) "url": "/" // required }},You can add other fields based on your needs and specifications, so long as it does not interfere with the Lambda integration, if you’re using the multiple-author solution.
To familiarize yourself with the rules around custom embeds and how they behave, review the following articles about custom embeds:
Live blog display
Beyond the technical aspects of this solution, you’re also concerned with how your live blog looks to your end user. Because you’re headless, you must strategize on how to manage these types of articles.
Limitations
As we are not creating a standalone live blogging solution, but a solution on top of already-existing products, you must take several items into consideration.
Content elements limit
It’s important to note that content elements per story are at a maximum of 300 referents on Composer. Also, if there is a need to have that many fragments in a single story, you may need to implement a “load more” or pagination.
If the live story has the need to go beyond the limitation, there is a way around it:
- Optimize content elements: Consider removing entries that are older than X days. This can help in slimming down the content_elements. It’s worth noting that typical users may not navigate back through thousands of fragments, so older data might not be as crucial for current performance.
- Utilize collections: You could create a collection specifically for live stories. By adding tags to these stories, it allows for a more streamlined and performant access. This method can help distribute the load and improve the overall user experience.
- Link stories: After the limit is reached, you can add a link in a live blog fragment to take you to the new story.
Rate Limit
Each client within Arc XP has a rate limit in front of the Arc XP APIs based on their expected traffic. The live blogging solution is also counting towards the Draft APIs rate limit. Specifically the setup for Multiple Authors can have an impact and needs to be considered.
Update time
This live blogging solution is not a real-time solution, which provides the end-user with rapid updates. The base for this solution is a regular Arc XP story in Composer and is treated as such by the front-end caching layers in place.
Parent article
During the active time of authors contributing to the multiple-author solution, the parent article should stay untouched. There is a risk involved with making changes while in the background, new drafts are being created and published by the IFX integration.
Any changes to the parent article should be communicated to the child authors to pause; otherwise, there is a risk of loosing changes or half finished changes being published.
Improvement ideas (custom)
Schema.org integration
To make sure search engines know about your ongoing and past live blogs, providing a Schema for it is a great addition. With this Schema the search engines will know to identify ongoing live blogs and add a “live” label to the entries. Providing the content of the story in a LiveBlogPosting and liveBlogUpdates will also help the crawlers understand the content on the page.
If you scroll all the way to the bottom you will see an example of Schema.org: LiveBlogPosting
Pinning
If there are specific key posts in your live blog that you want to highlight, or deem important for the user to read first, pinning them would be a great addition.
You would need to update the Power Up with a boolean field if it should be pinned or not, where in the front-end code, you would pull those entries out and move them to the top. They can stay in reverse chronological order or you can add another timestamp to the pinning functionality to allow you to have them in a specific order.
Share bar and anchor tags
Depending on the content in your live blog and the complexity of each entry, you might want to allow for users to share specific entries, which when clicked on the shared-url are moved to the shared entry. For this, you need to follow the usual anchor-tag rules and extend the front-end output of the Timestamp with a Share Bar.
Note that if you have lazy loading or other asynchronous content, the coordinates will change after or while the browser is moving a user to the coordinates. The alternative would be to turn off lazy loading or to add Javascript that will refresh the coordinates after lazy/asynchronous content is being loaded
Timeline
To keep an overview of the entries created, you can create a Timeline based on the Timestamps in the content elements. It can be a separate block to enhance the experience from the Article Body in the right rail (depending on the Layout) or at the top of the live blog.
The Timeline could be enhanced by creating anchor-tags for each timestamp and a teaser-text. The teaser text could be generated by the first text-element after the Power Up or manually curated on the Power Up in Composer.