Audience Insights Architectural Overview
Introduction
The back-end infrastructure of the Arc Audience Insights service is designed to be very performant. This document discusses that architecture at a high level to give an understanding of why the associated APIs work the way they do.
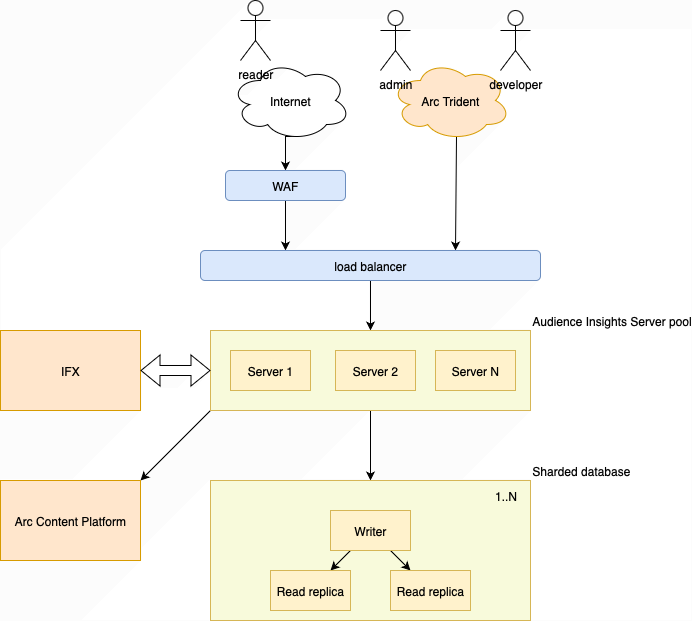
User Types
Reader
A reader is a person consuming your content. The purpose of Audience Insights is to collect data to be used for personalizing the user’s experience.
In the initial release users are expected to be signed into Arc’s Identity product while future releases will enable a publisher to bring its own
IdP into the mix. For this reason the Audience Insights database is separate from the main Arc Identity database, and data from the two (databases)
is not mixed.
Admin
An admin is a person that signs into Arc’s hosted admin applications. Examples of admin users include customer services reps and marketers.
Developer
In the context of this document, a developer is an employee/agent of the publisher. This developer may be a person or an external (to Arc) application
that interacts with Audience Insights data via APIs.
IFX
IFX is Arc’s integration framework. It enables a publisher to insert custom logic into various Arc business processes. In the case of Audience Insights The Key-Value feature can trigger an IFX integration when a user submits data for a certain key. For example the user could have requested to be signed up for a newsletter, an event which Arc does not support directly. Instead you may create an IFX integration to communicate this information to your ESP. IFX integrations are invoked asynchronously and are expected to call back to Audience Insights to store data on the user’s account.
Arc Content Platform
Audience Insights is integrated with the rest of the Arc Content Platform. It is not necessary for you, as a developer/admin, to configure this, but do know that Audience Insights may use some of your downstream rate limits. An example of this is the article bookmarking feature which takes as its input only the ANS ID of the article being bookmarked. Behind the scenes the bookmark API calls on both Arc’s Content and Site APIs for meta data and, while caching is involved within the Audience Insights application, will consume some of your capacity associated with those services.
Audience Insights Server Pool
The Audience Insights back-end application is designed to be elastic. This means that load/traffic to the application is automatically monitored and that instances of the application will be added/removed to/from the pool as demand changes. Adjustable(by Arc) rate limits are enforced at the application level and, although high, these limits are not infinite. You should prepare your applications to be able to deal with 429 type HTTP responses at any time.
Sharded Database
Audience Insights makes use of a sharded database. What that means is that it will scale up/down with demand just like the server pool. It is important to note, in the above figure, that each shard consists of a single writer and two read replicas. This means that there is a slight lag between writing to the database and being able to read back the data. Arc has chosen to deal with this fact by returning 202 type HTTP responses to PUT, POST and DELETE requests to indicate that the data has been written but not yet replicated. Arc estimates typical replication lags to be around one second.
Rate limits
Rate limits are set to provide clients performative, stable user data storage functionality with additional tiers available to offer scalable options for clients who require higher throughput. For customers leveraging the Identity product, a free basic tier will be included, allowing up to 100 requests per second (RPS) for all Audience Insights APIs. Additional RPS tiers will be available for purchase to meet varying client needs and usage patterns.