Artificial intelligence bots, particularly those powering large language models, are rapidly changing how content is discovered and used online. For news publishers, these bots present both opportunities and challenges, from traffic shifts to intellectual property questions.
Arc XP powers more than 1,000 media websites, totaling over a billion page views each month. Combining our industry insights with others — including Stanford Graduate School of Business [1] and DataDome’s Bot Security Traffic reports — we see clear patterns emerging.
AI Tools & Web Traffic
AI bots differ from traditional search and social traffic: their responses are often self-contained, meaning fewer readers click through to original sources. Stanford research [1] found click-through rates from AI chatbots at just 0.33% and AI search engines at 0.74%, compared to 8.6% for Google Search. This shift raises unique concerns about audience reach, monetization, and brand visibility.
The growing presence of AI web crawlers
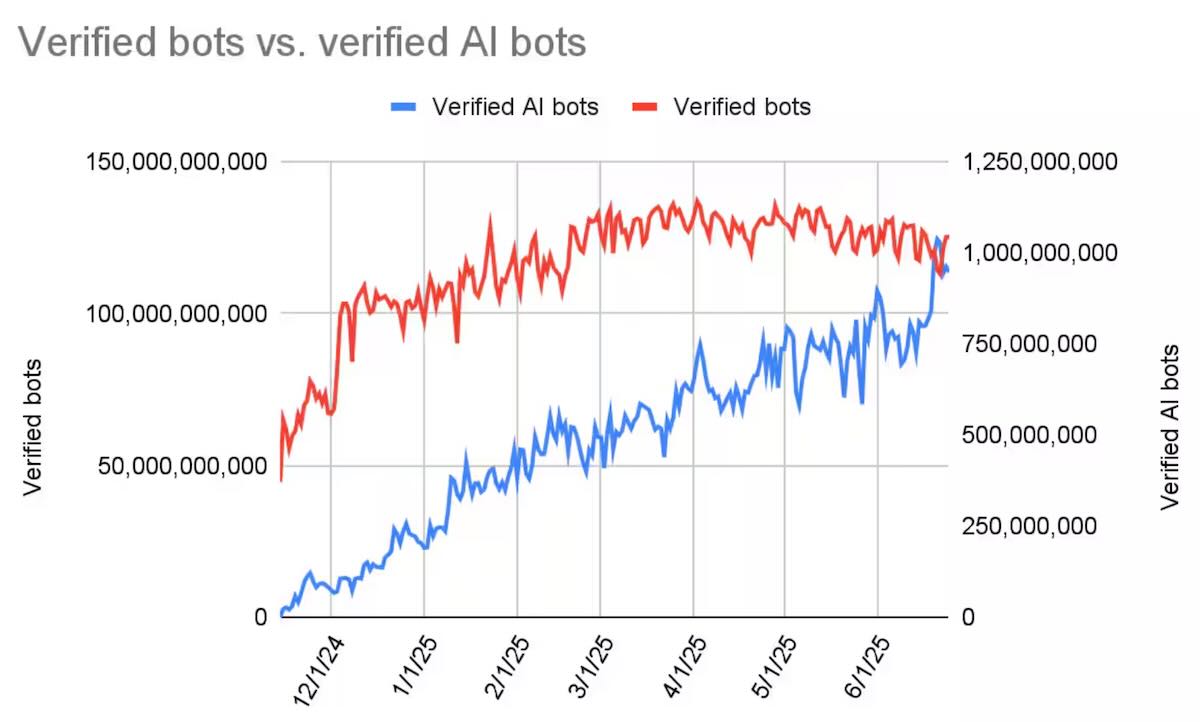
Source [2]
To power consumer-facing chatbot experiences, AI companies use bots to crawl media websites — using that data to train and inform responses for LLMs.
Arc XP’s CDN (powered by Akamai’s network) observed a 300% year-over-year jump in AI-driven bot traffic. By late 2024, AI scrapers made up only about 0.27% of total traffic, yet that translates to billions of requests per day and is growing steadily. Media and publishing sites are particularly affected; they are 7× more likely to see AI bot traffic than the average website.
This dramatic growth shows no signs of abating, and new bots are appearing almost weekly. Some are relatively well-behaved (respecting site’s robots.txt rules), while others are more aggressive – but the intent behind these crawlers varies widely, from broad content scraping for AI model training to real-time data gathering for AI agents. It’s a surprising fact that, 65% of these simple bots go completely undetected — meaning 2 out of 3 organizations are at risk of bot attacks [4] without even knowing.
How news publishers are responding
Media organizations have taken notice of these AI crawlers and are reacting in different ways, mostly with a defensive strategy. One widespread response has been to update robots.txt rules – the standard way websites tell bots what they can or cannot crawl. A recent analysis by the News Homepages [3] project (palewire) surveyed the robots.txt files of 1,154 news sites worldwide. It found that over half (54.2%) of these news publishers have opted out of at least one AI-oriented crawler like OpenAI’s GPTBot, Google’s AI bot, or Common Crawl.
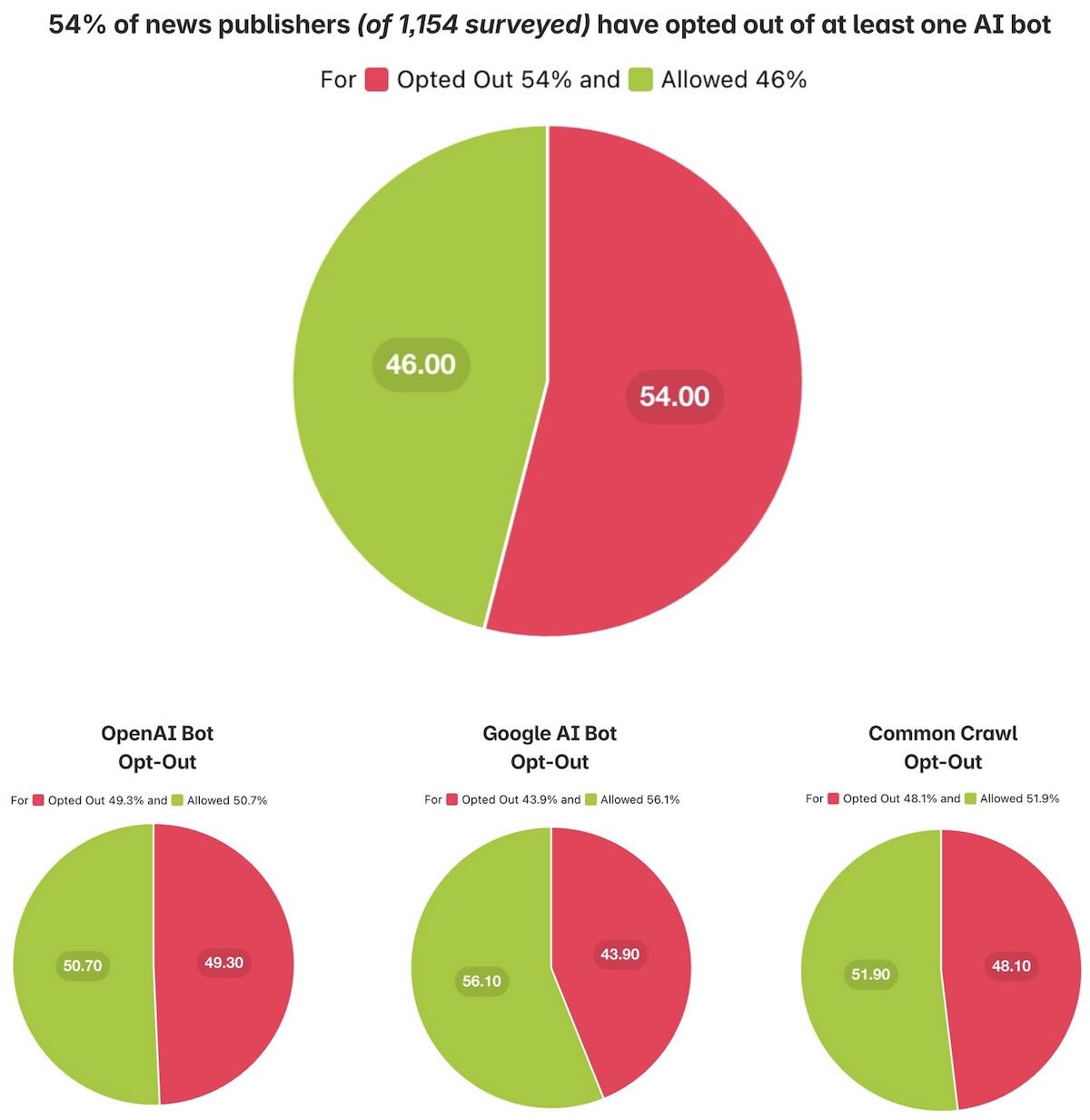
Source [3]
Nearly half (49.4%) of news sites disallow OpenAI’s GPTBot outright—the most-blocked AI crawler in the sample, likely because ChatGPT dominates daily AI chatbot usage among readers. Close behind, about 47.8% block Common Crawl (the non-profit web crawler whose data often feeds AI projects) and 44.0% block Google’s AI crawler. In total, 626 news sites (54.2%) have added rules to stop at least one of these bots from scanning their content.
This wave of robots.txt opt-outs began in mid-2023 and has grown – for instance, major outlets like The New York Times, CNN, Reuters, and Australia’s ABC moved quickly to block GPTBot in August 2023. All told, roughly half of the news industry is now saying “no thanks” to one or more AI scrapers on their sites.
robots.txt is ineffective to block AI bots
Robots.txt is just a suggestion for crawlers/bots, not an effective way to enforce/block. As highlighted in Stanford GSB research [1], many publishers view robots.txt as
“not fit for purpose. It only serves as a leakage point.”
Bots can still scrape content indirectly or bypass robots.txt entirely, and some publishers who opted out found their content ingested through third-party aggregators. Perplexity, for example, is alleged to ignore robots.txt altogether [1].
DataDome, an industry-leading Bot Security and Management service provider’s latest Bot Security Report [4] states:
“Only 8.44% were fully protected and successfully blocked all bot requests.”
Revenue concerns
Executives worry about AI using content without sending traffic back.
“The question isn’t whether AI will change how news works – it already has. The question is whether we get paid for it.” [1]
That concern stems from measurable differences in audience behavior. Traditional search engines have long provided a reliable stream of visitors, with about 8.6% of users clicking through to original sources [1]. By contrast, AI search engines return just 0.74% click-through, and conversational AI tools such as chatbots barely reach 0.33% [1].
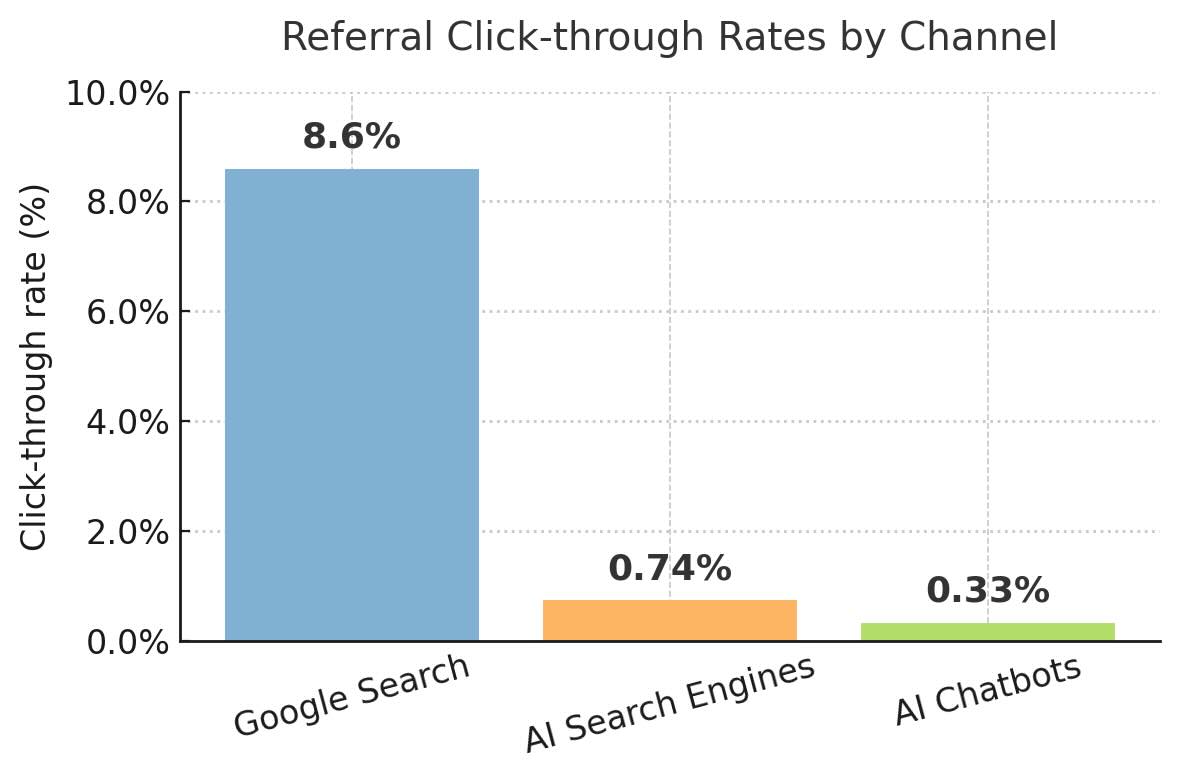
Source [1]
These new distribution models often satisfy readers directly in the AI interface, leaving publishers out of the audience journey entirely and with the loss of inbound traffic.
For ad-supported outlets, fewer visits translate directly to lost ad impressions and reduced CPM revenue. Subscription-driven publishers face a similar challenge: fewer site visits mean fewer opportunities to convert casual readers into paying customers.
Publishers are experimenting with new and diverging strategies
Industry responses are fragmented and, in many cases, experimental.
Some publishers have experimented with direct licensing agreements, granting structured access to AI companies. However, early deals are already raising concerns that they set unsustainably low compensation benchmarks for the industry, potentially weakening long-term bargaining power.
Some publishers are pursuing litigation, most prominently the New York Times lawsuit against OpenAI, aiming to establish clear legal boundaries around content scraping and AI training.
Others are experimenting with bot paywalls that grant AI companies paid access to articles. Marketplaces like TollBit, ScalePost, ProRata.ai, miso.ai , and Particle have emerged to facilitate these transactions and help publishers monetize data feeds directly.
At the same time, industry groups and major publishers are lobbying for government regulation to create clearer rules for AI data usage and compensation frameworks. Similar to early years of Uber, we’re seeing regional or country-specific push back and responses.
This divergence underscores the uncertainty of the moment: while some organizations see opportunity in new distribution channels, others see existential risk and are focusing on protecting intellectual property above all else.
Arc XP’s view: active monitoring and future-proofing
Arc XP is actively monitoring the surge in AI-driven bots and evolving our platform capabilities to help customers navigate this new landscape. We believe there’s no single, permanent answer to how publishers should handle AI crawlers; the industry is still experimenting, and so are the bots themselves.
Every Arc XP site is protected out of the box by our baseline Arc Security, which safeguards customer properties from malicious traffic and ensures that readers are never impacted by unexpected traffic surges—including those driven by AI bots. Customers can further tighten their traffic to content sources from bad actors and unexpected crawler traffic on our platform (see guide). This platform-level guarantee is core to how we design and operate Arc XP, so publishers can stay focused on their journalism while we keep performance stable and secure.
Building on this baseline protection, our strategy is to provide customers with a portfolio of strategies, experimentation options, and tools to help them adapt quickly to the rising AI bot trend and its evolving threats and opportunities. This starts with Edge Integrations — our platform foundation for offering best-in-class solutions right at the network edge.

Our first integration, DataDome, delivers robust bot management capabilities today. It’s one step in a journey we’ve been on for years—investing in security and performance at the edge to protect publishers’ traffic and ensure uninterrupted reader experiences. DataDome builds on that foundation, giving us a flexible platform to expand into new capabilities, with more advanced and granular customer control, including future monetization opportunities as the industry matures. See DataDome & Arc XP partnership press release and DataDome Integration documentation to learn more.
The reality is that we’ll likely see hundreds of new bot types and behaviors in the coming months and years, from aggressive scrapers to AI-powered agents that look and act like real human traffic. While we can predict some trajectories, it’s still early, and flexibility is key. Arc XP has invested in the infrastructure, partnerships, and roadmap so that our customers can focus on their journalism while we help handle this rapidly changing traffic environment.
References
-
[1] The News Pipeline: Economic and Strategic Implications of AI for News Distribution (Webb & Nair, Stanford GSB, May 2025) - Get a copy of the paper from authors
-
[2] AI and LLM Bot Management Has Become a Business-Critical Issue (Akamai Blog)
-
[3] “News Homepages” - an open source project tracks 1000+ news sites (by palewire, data-driven Reuters journalist)